
半导体从入门到放弃(中)—— 局域性原理与芯片设计
半导体芯片是现代电子设备的核心,从电视遥控器到超级计算机,无不依赖于这些微小的硅片。然而,芯片设计和制造是一个复杂的过程,涉及深厚的物理、化学知识和精密的工程技术。本篇文章旨在为读者提供一个全景式的了解,涵盖从半导体材料的基本原理到数字电路设计,以及从芯片体系结构到生产工艺的各个环节。
需要注意的是,本篇文章并不会深入探讨具体的设计方法或实现手段,除非特别举例说明。本文的目标是帮助读者理解半导体行业的核心概念,让你在面对与芯片相关的新闻或话题时,能够辨别出无良媒体的误解或错误。然而,读完这篇文章后,读者可能不会成为半导体行业的专家,甚至连入门都谈不上。但会对芯片设计背后的原理有更清晰的认识。
目录导航
- 半导体从入门到放弃(上)—— 半导体和数字电路
- 半导体从入门到放弃(中)—— 局域性原理与芯片设计
- 半导体从入门到放弃(下)—— 量产技术(未完成)
局域性原理
物理学家眼中
在经典电磁场理论中,电场和磁场通过 麦克斯韦方程组 描述。电磁相互作用并不是瞬时传播的,而是通过电磁波以 有限的光速 进行传播。电磁波的传播速度直接体现了局域性原理:一个物体在某个时刻产生的电磁波只会在光速允许的范围内影响其他物体,超出该范围的物体无法感知到这一相互作用。
坡印亭矢量(Poynting vector)是电磁场中描述能量传递的向量,它定义了电磁能量在空间中如何随时间传播。其公式为: \(\mathbf{S} = \mathbf{E} \times \mathbf{H}\) 其中 E 是电场强度,H 是磁场强度。坡印亭矢量的方向代表能量流动的方向,大小表示电磁能量的传输速率(能流密度)。电磁能量流的传播是局域的,即能量传递遵循空间中的场和场之间的相互作用,并且传递 不会超越光速。电磁场的这种 局域性 反映了能量与作用力无法瞬时传递到无限远处,而是有速度限制的,这也是因果律的体现。
在 广义相对论 中,时空中的事件只能影响位于其 光锥 内的事件。光锥定义了从某个时刻出发,光以光速传播能够到达的所有点的范围。光锥以外的区域是无法被该事件影响的,体现了相对论中的局域性。
在 量子场论 中,电磁场是一个 规范场,其量子化后的激发对应于 光子。光子是电磁力的传递者,即任何带电粒子之间的相互作用是通过光子交换来实现的。量子场论通过光子与带电粒子的相互作用解释了电磁现象。
根据量子场论的原则,电磁场的量子化意味着电磁相互作用是由光子的场量子在特定的时空点中以局域的方式激发、传播和相互作用的。也就是说,电磁场只在它所作用的局部时空区域内起作用,并且光子只能在 有限的范围内 进行传播,受 光速的限制。
在计算机科学家眼中
根据物理学中的局域性原理,信号和信息的传播速度是有限的,特别是受光速限制。这意味着在计算机系统中,处理器、内存和存储设备 之间的通信速度不能超越这些物理限制。如果处理器频繁访问远距离的存储单元(如主存或磁盘),由于信号传输时间长,系统性能将受到严重影响。因此,设计计算机系统时,必须依赖局域性原理将常用数据尽可能存储在靠近处理器的高速缓存中。
计算机的局域性原理主要体现在两个方面:
- 时间局域性
- 空间局域性
时间局域性指的是,如果某个数据或指令在某一时间点被访问过,那么它很可能在不久之后再次被访问。这意味着 最近使用的数据更有可能再次被使用。在现代计算机架构中,我们可以利用缓存存储最近访问过的数据,以便快速再次访问。
空间局域性指的是,如果某个地址的数据被访问,那么它附近的地址也很有可能在不久后被访问。这种访问模式通常表现为 相邻的数据或指令被连续访问。这使得系统可以通过预取机制或批量加载数据来提高性能。
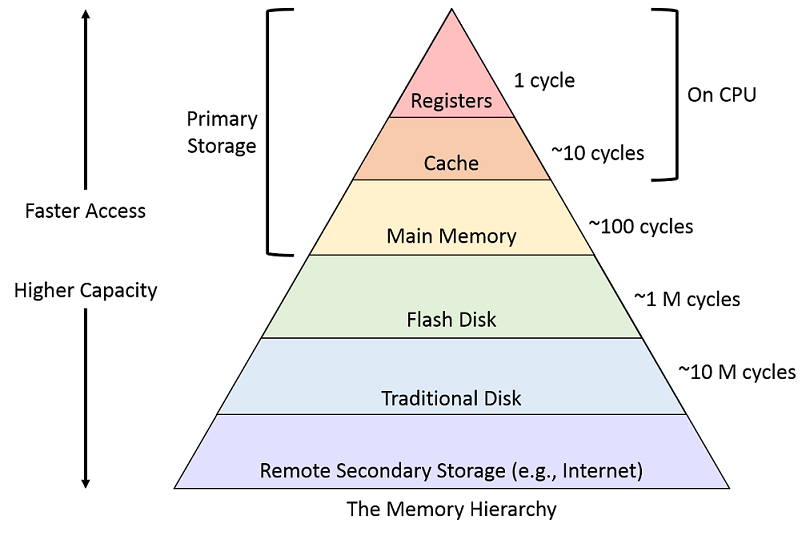
为了让处理器不会被存储设备的性能拖累,我们不能让所有的电路都运行在相同的时钟频率上。 否则我们必须向最慢的设备妥协。而这是 物理性质决定的,不随人的意志所转移。
我们可以看到像规模巨大的超级计算机,虽然吞吐量很大,但是延迟通常也很大,无法满足实时计算的需求。即使超级计算机的设计者,花了非常大的力气,从缓存和网络拓扑角度在优化它的延迟,物理限制依然明显地存在。因此并不存在一个 银色子弹将算力完全量化。我们必须深入分析我们所要运行的计算的特点,再根据它去权衡我们如何设计电路,才能达到最高的执行性能或效率。
CPU 入门
流水线设计
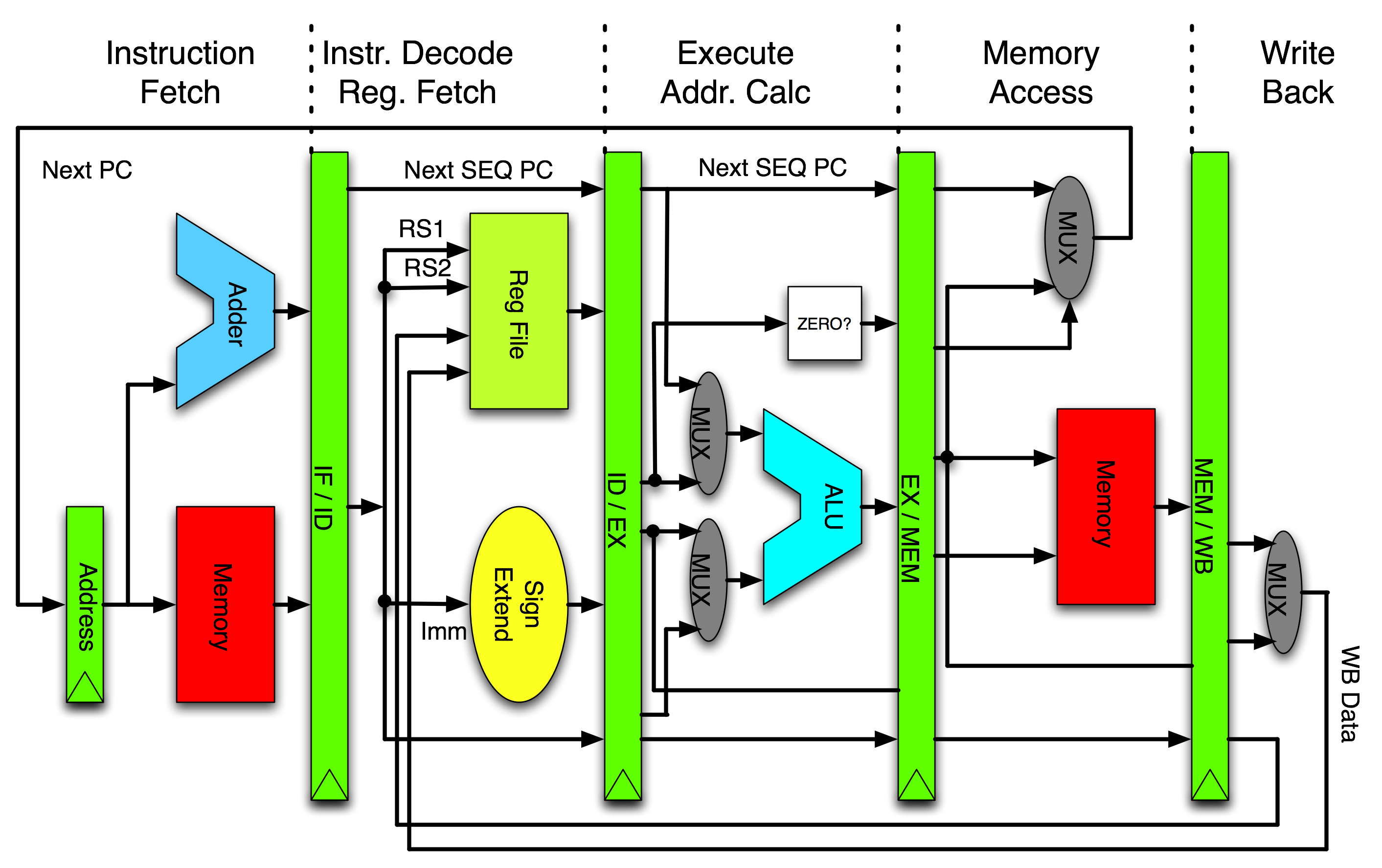
流水线设计 是一种在处理器中用于提高性能的关键技术,它通过将指令的执行过程分解为多个阶段,并在这些阶段之间并行处理多条指令,从而提高处理器的整体吞吐量。通过这种方式,流水线能够在每个时钟周期内处理多个指令,最大化资源的利用率。我们可以通过 MIPS 5 阶流水线 的例子来简单介绍流水线的工作原理,以及它如何提高性能。
MIPS 处理器是一种经典的精简指令集(RISC)架构,它的常见参考实现使用了 5 级的指令流水线来提高性能。MIPS 处理器的 5 个流水线阶段包括:
- 取指阶段(IF, Instruction Fetch):从内存中取出当前要执行的指令,并存入指令寄存器。
- 译码阶段(ID, Instruction Decode):对取出的指令进行译码,识别指令的操作码,并读取相应的操作数。
- 执行阶段(EX, Execute):对指令进行具体的算术运算或逻辑运算。如果是访存指令,则计算出存储地址。
- 存储访问阶段(MEM, Memory Access):如果是读/写内存操作,在此阶段完成数据的加载或存储。
- 写回阶段(WB, Write Back):将运算结果或从内存中读取的数据写回寄存器。
每条指令必须依次经过这五个阶段才能完成执行。
在传统的非流水线处理器中,一条指令必须执行完所有的 5 个步骤,才能执行下一条指令。换句话说,处理器每次只能执行一条指令,这会导致大量的资源浪费。例如,当处理器在内存中读取数据时,运算单元处于闲置状态。
由于每个单元的规模都变小了,其能支持的运行频率也在提升,使用多阶流水线的处理器往往能达到更高的运行频率,从而实现更高的处理器性能。
数据竞争
然而,流水线并不是越深越好的。当一条指令的执行依赖于前一条指令的结果时,如果两条指令同时处于流水线中,可能会 导致数据错误。这被称为「数据冒险 (Data Hazard)」。
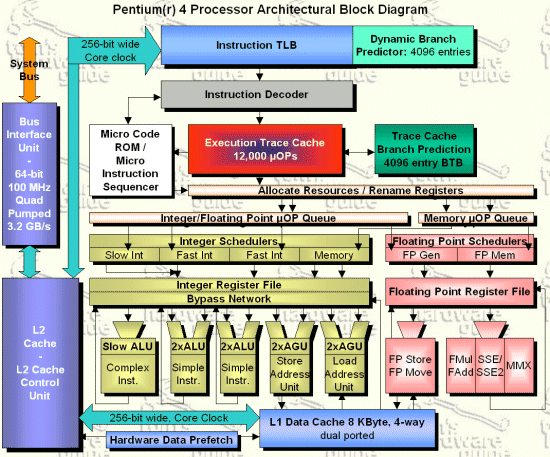
Intel 的 Pentium 4 处理器采用了一个超深流水线设计,称为 NetBurst 微架构,其流水线深度达到了 20 阶以上。这种设计目的是允许处理器以更高的频率运行,从而提升性能。理论上,通过将每个流水线阶段的任务分解为更小的子任务,处理器可以在更短的时钟周期内完成每个步骤,使得时钟频率得以提升。然而,这种过于深的流水线设计带来了 数据冒险 问题的严重加剧。
流水线的深度直接影响到数据冒险问题的严重程度。在更深的流水线中,由于每条指令的执行分解得更加细致,每条指令所需的处理时间(即从取指到写回的时长)增加,指令之间的数据依赖性可能会跨越更多的时钟周期。这会导致指令之间的依赖关系更加复杂,从而加剧数据冒险问题的发生。当然处理器可以选择原地暂停(流水线空泡 Bubble)来避免数据冒险引起计算错误,但这不就让我们的流水线效率大幅下降了吗?更何况在现代处理器中,还会引入类似分支预测等技术,数据冒险还需要触发分支预测的清空,会带来更大的性能损失。
为了降低数据冒险问题带来的影响,寄存器重命名技术被提了出来。
寄存器重命名的核心思想是,将程序中虚拟寄存器与物理寄存器分开。在现代处理器中,虽然架构中定义的寄存器数量有限,但物理上处理器通常有 比架构寄存器更多的物理寄存器。寄存器重命名通过将虚拟寄存器映射到这些额外的物理寄存器,从而消除虚拟寄存器之间的假依赖关系。
假设有以下指令序列:
1. ADD R1, R2, R3 ; R1 = R2 + R3
2. SUB R1, R4, R5 ; R1 = R4 - R5
3. MUL R6, R1, R7 ; R6 = R1 * R7
- 第 1 条和第 2 条指令都写入寄存器 R1,理论上会导致 写后写冒险(WAW),因为它们都尝试写入相同的虚拟寄存器 R1。
- 第 3 条指令依赖于第 2 条指令的 R1 值,可能导致 写后读冒险(RAW)。
传统上,为了防止这两种问题,我们必须等待前一条指令完全执行完才能恢复流水线执行。如果使用寄存器重命名,处理器可能会为每条指令分配不同的物理寄存器:
- 第 1 条指令的 R1 被重命名为物理寄存器 P1。
- 第 2 条指令的 R1 被重命名为物理寄存器 P2。
- 第 3 条指令的 R1 操作数从 P2 读取,而不是从 P1 读取。
并行执行
超标量(Superscalar)和 SIMD(Single Instruction, Multiple Data,单指令多数据)是现代处理器中两种关键的并行执行技术,它们通过不同的方式提升处理器的计算性能。
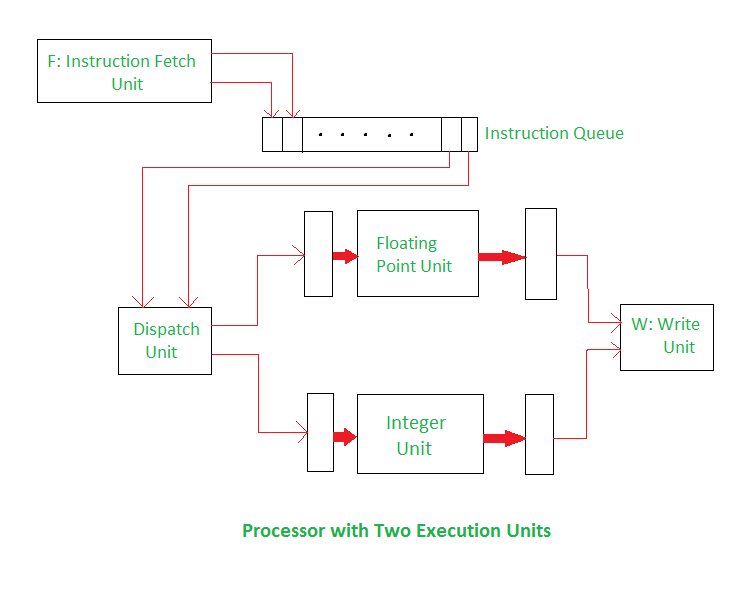
超标量技术允许处理器在每个时钟周期内同时发射和执行多条指令,而不是每个周期只执行一条指令。由于一些指令例如乘法可能需要多个周期才能执行完成,而这时候如果再来一条加法指令,会认为流水线中 EX 阶段已经满载需要等待才能继续执行。但是如果我们在 EX 阶段引入多个计算单元,可以并行处理多个独立的指令,从而增加处理器的吞吐量。
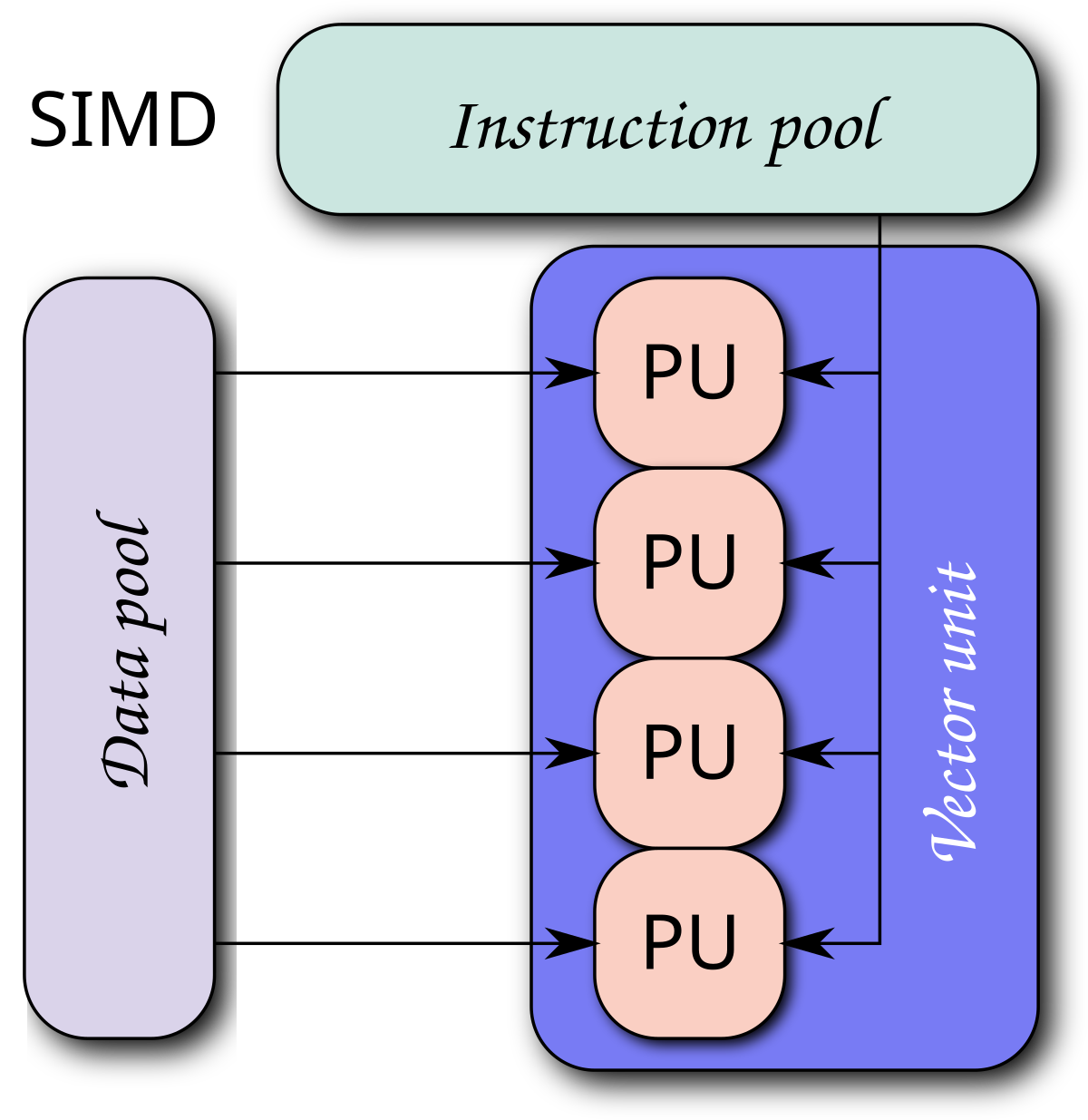
进一步地,图像处理、视频解码、科学计算中大量计算(比如向量和矩阵),是对一组数据进行相同的加法或乘法运算。SIMD 技术使得处理器能够同时存储多个数据,通过一条 SIMD 指令可以同时对这些向量数据进行并行操作,从而增加处理器的吞吐量。
这些指令的本质其实是利用了局域性原理中的空间局域性,因为我们可以用吞吐量换延迟,先成批成批地将内存中的数据搬运到缓存中,当我们要进行批量运算时,就不需要考虑 DRAM 读取的延迟,从而提升了处理器的性能。
GPU 入门
硬件 T&L
在图形计算中,一个里程碑式的发明就是硬件 T&L(Transform & Lighting,变换和光照)。
其中变换指的是对几何体的位置、旋转、缩放等操作,将三维坐标转换为二维屏幕坐标,通常是一个矩阵乘加运算。而光照计算是指根据场景中的光源、材质以及视角来计算物体表面的光照强度和颜色,通常是一系列的向量运算。

在传统的图形渲染管线中,这些计算通常由 CPU 执行,然而这些计算算法非常单一,要处理的坐标数量非常多,并不适合 CPU 的串行执行模式。1999 年 NVIDIA 推出了 GeForce 256,其将硬件 T&L 引入了 GPU 的概念,这使得图形性能得到了飞速的提升。
由于 T&L 算法是固定的,我们只需要堆叠大量的矩阵乘加和向量运算单元,就可以提升其处理的吞吐量。它使得 GPU 从一个仅仅负责绘图的设备,变为一个可以处理复杂几何和光照任务的高效并行计算设备。这为后来的 可编程着色器 和 通用计算 打下了基础。
可编程着色器
然而随着图形技术的演化,大家对 3D 图形的处理愈发复杂。2001年,随着 DirectX 8 和 OpenGL 标准的更新,可编程着色器第一次被引入消费级图形处理器。可编程着色器的出现使得开发者可以通过编写自己的小程序,来控制顶点和像素的渲染方式,从而创建复杂的视觉效果。于是 GPU 变成了一种 适合批量执行小程序 的硬件结构。

GPU 的架构与 CPU 相比,显著的不同在于其强调并行计算。GPU设计了大量简单的计算单元(流处理器),每个单元负责执行多个线程,从而可以同时处理大量的小任务(如着色器程序)。GPU 的这种并行性使其在大规模数据处理任务中能够保持极高的吞吐量。
同时,GPU 的缓存设计与 CPU 不同,它更注重支持大规模数据的批量传输和并行访问。GPU 处理的数据量巨大,尤其是在图形渲染中,需要处理成千上万个像素、顶点和纹理。因此,GPU 的缓存架构专注于高带宽的批量数据处理,能够最大化数据传输的吞吐量。
GPGPU
在早期的图形渲染管线中,像素着色器主要用于处理每个像素的颜色、纹理、光照等视觉效果。随着可编程着色器的引入,开发者逐渐意识到,像素着色器不仅可以用于图形渲染,还可以执行其他类型的并行计算任务,尤其是在需要处理大量数据的场景下。例如,洋流、大气仿真作为一种复杂的科学运算,涉及大量的浮点运算和向量场计算,开发者发现这些任务的计算模式与图形渲染中的像素处理非常相似。于是开始尝试通过构造一个简单的大于屏幕尺寸的三角形,并在里面填充像素的形式,来进行这些科学运算的模拟。
这推动了计算着色器(Compute Shader)和 GPGPU 的诞生。这也使得后续基于 GPU 进行神经网络深度学习等任务变得可能。
小结
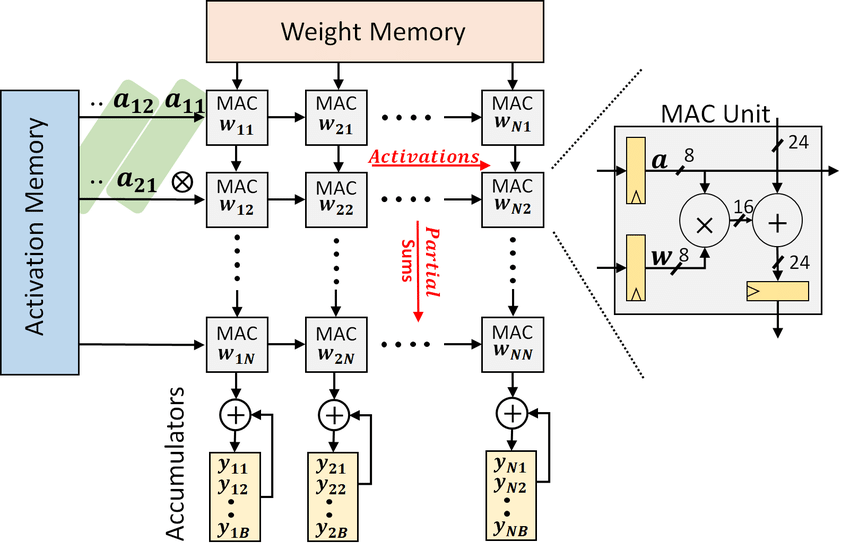
GPGPU 虽然显著提升了神经网络等并行计算任务的性能,但它并不是执行这些任务的最优手段。为了适应深度学习等领域中对矩阵运算的极高需求,今天的 GPU 架构进行了进一步的优化,尤其是引入了像脉动阵列 (Systolic Array) 这样的硬件结构,以提升对矩阵乘加运算的性能。这种架构的变化代表了 GPU 在满足更广泛任务时的一种体系结构的取舍。甚至我们有进一步舍弃 GPU 架构,完全为了神经网络架构优化的 NPU 或 TPU 芯片。这些微架构的差异极大显示了芯片设计上的差异对性能的巨大影响。在下个章节我们会讨论如何通过芯片的生产工艺对芯片又有哪些巨大的影响。