
A Walkthrough of Ruby 3 Scheduler
A Failed Proposal
When preparing for RubyConf China 2020, I checked the recent patch for Fiber Scheduler in Ruby. When inspecting the example Scheduler, I found it’s using IO.select API in Ruby. IO.select API has multiple different implementations in Ruby. It may probably call poll, large-size select, or the POSIX select in the operating system. So I try to implement the I/O scheduler with faster syscalls like epoll, kqueue, and IOCP.
I proposed an issue to Ruby, but it was rejected. The major problem is that, the IO.select API is stateless. Without stateful registration, the performance is even getting lower when using epoll. It’s proved by the benchmark written by Koichi Sasada. After discussing with Samuel Williams on Twitter, he recommended me to directly hook the implementation of Scheduler, which the registration process is stateful. So I start a PoC gem development for Ruby 3 Scheduler interface.
Implement a Scheduler
The Ruby version mentioned in this article is:
ruby 2.8.0dev (2020-08-18T10:10:09Z master 172d44e809) [x86_64-linux]
The basic scheduler example is from the unit test used in Ruby. In general, this is a Proof of Concept of Ruby 3 Scheduler instead of a production-ready one. Mainly, it’s using IO.select for I/O multiplexing. So from this backbone, we are going to implement a better-performed Ruby Scheduler.
We have to do some C programming to support other system calls. But the first thing is to implement a C method that could be compatible with the original implementation.
Fallback to Ruby IO.select
For select/poll API, you don’t have to initialize a file descriptor first or register and deregister the interest during runtime. All you need to do is to run the select with the proper number of IOs when triggered.
VALUE method_scheduler_wait(VALUE self) {
// return IO.select(@readable.keys, @writable.keys, [], next_timeout)
VALUE readable, writable, readable_keys, writable_keys, next_timeout;
ID id_select = rb_intern("select");
ID id_keys = rb_intern("keys");
ID id_next_timeout = rb_intern("next_timeout");
readable = rb_iv_get(self, "@readable");
writable = rb_iv_get(self, "@writable");
readable_keys = rb_funcall(readable, id_keys, 0);
writable_keys = rb_funcall(writable, id_keys, 0);
next_timeout = rb_funcall(self, id_next_timeout, 0);
return rb_funcall(rb_cIO, id_select, 4, readable_keys, writable_keys, rb_ary_new(), next_timeout);
}
We spent ten lines of C code for a single line of Ruby code. It makes no sense, but it gives the possibility for us to call other I/O multiplexing syscalls including epoll and kqueue, we add 4 C methods to the Scheduler API as following:
Scheduler.backend
scheduler = Scheduler.new
scheduler.register(io, interest)
scheduler.deregister(io)
scheduler.wait
#include <ruby.h>
VALUE Evt = Qnil;
VALUE Scheduler = Qnil;
void Init_evt_ext();
VALUE method_scheduler_init(VALUE self);
VALUE method_scheduler_register(VALUE self, VALUE io, VALUE interest);
VALUE method_scheduler_deregister(VALUE self, VALUE io);
VALUE method_scheduler_wait(VALUE self);
VALUE method_scheduler_backend();
void Init_evt_ext()
{
Evt = rb_define_module("Evt");
Scheduler = rb_define_class_under(Evt, "Scheduler", rb_cObject);
rb_define_singleton_method(Scheduler, "backend", method_scheduler_backend, 0);
rb_define_method(Scheduler, "init_selector", method_scheduler_init, 0);
rb_define_method(Scheduler, "register", method_scheduler_register, 2);
rb_define_method(Scheduler, "deregister", method_scheduler_deregister, 1);
rb_define_method(Scheduler, "wait", method_scheduler_wait, 0);
}
Scheduler.backend is for debugging only, and the other 4 APIs would be injected into Scheduelr#run, Scheduelr#wait_readable, Scheduelr#wait_writable, Scheduelr#wait_any.
Using epoll and kqueue
There are three major APIs for epoll, epoll_create, epoll_ctl, and epoll_wait, which is quite easy to be understood. We just need to create the epoll fd when Scheduler initialization, and call epoll_ctl during registration and deregistration, then replace the original IO.select with epoll_wait.
#if defined(__linux__) // TODO: Do more checks for using epoll
#include <sys/epoll.h>
#define EPOLL_MAX_EVENTS 64
VALUE method_scheduler_init(VALUE self) {
rb_iv_set(self, "@epfd", INT2NUM(epoll_create(1))); // Size of epoll is ignored after Linux 2.6.8.
return Qnil;
}
VALUE method_scheduler_register(VALUE self, VALUE io, VALUE interest) {
struct epoll_event event;
ID id_fileno = rb_intern("fileno");
int epfd = NUM2INT(rb_iv_get(self, "@epfd"));
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
int ruby_interest = NUM2INT(interest);
int readable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WAIT_READABLE")));
int writable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WAIT_WRITABLE")));
if (ruby_interest & readable) {
event.events |= EPOLLIN;
} else if (ruby_interest & writable) {
event.events |= EPOLLOUT;
}
event.data.ptr = (void*) io;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &event);
return Qnil;
}
VALUE method_scheduler_deregister(VALUE self, VALUE io) {
ID id_fileno = rb_intern("fileno");
int epfd = NUM2INT(rb_iv_get(self, "@epfd"));
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
epoll_ctl(epfd, EPOLL_CTL_DEL, fd, NULL); // Require Linux 2.6.9 for NULL event.
return Qnil;
}
VALUE method_scheduler_wait(VALUE self) {
int n, epfd, i, event_flag, timeout;
VALUE next_timeout, obj_io, readables, writables, result;
ID id_next_timeout = rb_intern("next_timeout");
ID id_push = rb_intern("push");
epfd = NUM2INT(rb_iv_get(self, "@epfd"));
next_timeout = rb_funcall(self, id_next_timeout, 0);
readables = rb_ary_new();
writables = rb_ary_new();
if (next_timeout == Qnil) {
timeout = -1;
} else {
timeout = NUM2INT(next_timeout);
}
struct epoll_event* events = (struct epoll_event*) xmalloc(sizeof(struct epoll_event) * EPOLL_MAX_EVENTS);
n = epoll_wait(epfd, events, EPOLL_MAX_EVENTS, timeout);
// TODO: Check if n >= 0
for (i = 0; i < n; i++) {
event_flag = events[i].events;
if (event_flag & EPOLLIN) {
obj_io = (VALUE) events[i].data.ptr;
rb_funcall(readables, id_push, 1, obj_io);
} else if (event_flag & EPOLLOUT) {
obj_io = (VALUE) events[i].data.ptr;
rb_funcall(writables, id_push, 1, obj_io);
}
}
result = rb_ary_new2(2);
rb_ary_store(result, 0, readables);
rb_ary_store(result, 1, writables);
xfree(events);
return result;
}
VALUE method_scheduler_backend() {
return rb_str_new_cstr("epoll");
}
#endif
kqueue is similar. The only difference is the registration and waiting parts are the same API in BSD. It’s controlled by the parameter of kevent(), which is a little bit hard to understand.
#if defined(__FreeBSD__) || defined(__NetBSD__) || defined(__APPLE__)
#include <sys/event.h>
#define KQUEUE_MAX_EVENTS 64
VALUE method_scheduler_init(VALUE self) {
rb_iv_set(self, "@kq", INT2NUM(kqueue()));
return Qnil;
}
VALUE method_scheduler_register(VALUE self, VALUE io, VALUE interest) {
struct kevent event;
u_short event_flags = 0;
ID id_fileno = rb_intern("fileno");
int kq = NUM2INT(rb_iv_get(self, "@kq"));
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
int ruby_interest = NUM2INT(interest);
int readable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WAIT_READABLE")));
int writable = NUM2INT(rb_const_get(rb_cIO, rb_intern("WAIT_WRITABLE")));
if (ruby_interest & readable) {
event_flags |= EVFILT_READ;
} else if (ruby_interest & writable) {
event_flags |= EVFILT_WRITE;
}
EV_SET(&event, fd, event_flags, EV_ADD|EV_ENABLE, 0, 0, (void*) io);
kevent(kq, &event, 1, NULL, 0, NULL); // TODO: Check the return value
return Qnil;
}
VALUE method_scheduler_deregister(VALUE self, VALUE io) {
struct kevent event;
ID id_fileno = rb_intern("fileno");
int kq = NUM2INT(rb_iv_get(self, "@kq"));
int fd = NUM2INT(rb_funcall(io, id_fileno, 0));
EV_SET(&event, fd, 0, EV_DELETE, 0, 0, NULL);
kevent(kq, &event, 1, NULL, 0, NULL); // TODO: Check the return value
return Qnil;
}
VALUE method_scheduler_wait(VALUE self) {
int n, kq, i;
u_short event_flags = 0;
struct kevent* events; // Event Triggered
struct timespec timeout;
VALUE next_timeout, obj_io, readables, writables, result;
ID id_next_timeout = rb_intern("next_timeout");
ID id_push = rb_intern("push");
kq = NUM2INT(rb_iv_get(self, "@kq"));
next_timeout = rb_funcall(self, id_next_timeout, 0);
readables = rb_ary_new();
writables = rb_ary_new();
events = (struct kevent*) xmalloc(sizeof(struct kevent) * KQUEUE_MAX_EVENTS);
if (next_timeout == Qnil || NUM2INT(next_timeout) == -1) {
n = kevent(kq, NULL, 0, events, KQUEUE_MAX_EVENTS, NULL);
} else {
timeout.tv_sec = next_timeout / 1000;
timeout.tv_nsec = next_timeout % 1000 * 1000 * 1000;
n = kevent(kq, NULL, 0, events, KQUEUE_MAX_EVENTS, &timeout);
}
// TODO: Check if n >= 0
for (i = 0; i < n; i++) {
event_flags = events[i].filter;
if (event_flags & EVFILT_READ) {
obj_io = (VALUE) events[i].udata;
rb_funcall(readables, id_push, 1, obj_io);
} else if (event_flags & EVFILT_WRITE) {
obj_io = (VALUE) events[i].udata;
rb_funcall(writables, id_push, 1, obj_io);
}
}
result = rb_ary_new2(2);
rb_ary_store(result, 0, readables);
rb_ary_store(result, 1, writables);
xfree(events);
return result;
}
VALUE method_scheduler_backend() {
return rb_str_new_cstr("kqueue");
}
#endif
An HTTP server example of using Scheduler
After implementing the Scheduler, we could now test the performance of the Scheduler, I wrote a very simple HTTP server as a benchmark.
require 'evt'
puts "Using Backend: #{Evt::Scheduler.backend}"
Thread.current.scheduler = Evt::Scheduler.new
@server = Socket.new Socket::AF_INET, Socket::SOCK_STREAM
@server.bind Addrinfo.tcp '127.0.0.1', 3002
@server.listen Socket::SOMAXCONN
@scheduler = Thread.current.scheduler
def handle_socket(socket)
line = socket.gets
until line == "\r\n" || line.nil?
line = socket.gets
end
socket.write("HTTP/1.1 200 OK\r\nContent-Length: 0\r\n\r\n")
socket.close
end
Fiber.new(blocking: false) do
while true
socket, addr = @server.accept
Fiber.new(blocking: false) do
handle_socket(socket)
end.resume
end
end.resume
@scheduler.run
The benchmark shows the original IO.select in Ruby would improve the performance by 3.33x when using non-blocking I/O, and using epoll would improve the performance by 4.21x. The server example is very short, when JIT-enabled, it’s not going to hit problems like ICache missing, so that the performance is 4.54x improved comparing to the original blocking I/O.
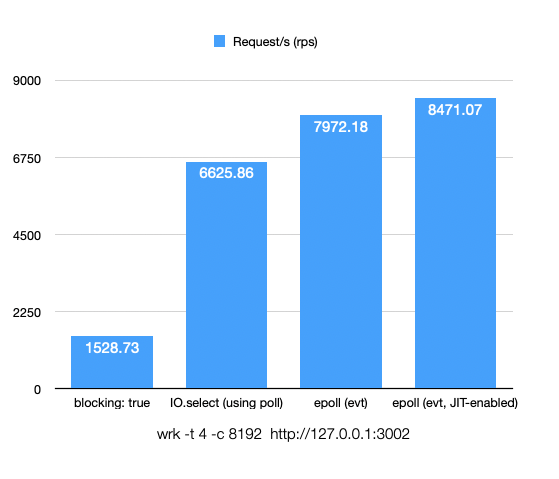
The benchmark is run under Intel(R) Xeon(R) CPU E3-1220L V2 @ 2.30GHz, and the program is single-threaded. With better CPUs, the difference between epoll and poll would be larger. Feel free to try the gem if you want.
Further Works
Further works include two parts. To improve the stability of the current API, and to support more syscalls including io_uring and IOCP. But to be honest, io_uring is still fine, but I have zero knowledge on Windows development. So feel free to give some advice or to provide some contribution.
Comments