
Ractor 下多线程 Ruby 程序指南
什么是 Ractor?
Ractor 是 Ruby 3 新引入的特性。Ractor 顾名思义是 Ruby 和 Actor 的组合词。Actor 模型是一个基于通讯的、非锁同步的并发模型。基于 Actor 的并发模型在 Ruby 中有很多应用,比如 concurrent-ruby 中的 Concurrent::Actor。Concurrent Ruby 虽然引入了大量的抽象模型,允许开发高并发的应用,但是它并不能摆脱 Ruby 的 GIL (Global Interpreter Lock),这使得同一时间,只有一个线程是活跃的。所以通常 concurrent-ruby 需要搭配无锁的 JRuby 解释器使用。然而,直接解除 GIL 锁会导致大量默认 GIL 可用的依赖出现问题,在多线程开发中会产生难以预料的线程竞争问题。
去年在 RubyConf China 的时候,我问 matz 说 90 年代多核的小型机以及超级计算机已经变得非常普遍了,为什么会把 Ruby 的多线程设计成这样呢?matz 表示,他当时还在用装着 Windows 95 的 PC,如果他知道以后多核会那么普遍,他也不会把 Ruby 设计成这样。
什么数据可以在 Ractor 间共享?
但是,历史遗留问题依然需要解决。随着 Fiber Scheduler 在 Ruby 3 引入来提高 I/O 密集场景下单一线程利用率极低的问题;我们需要进一步解决,计算密集场景下,多线程的利用率。
为了解决这一问题,Ruby 3 引入了 Ractor 模型。Ractor 本质来说还是 Thread 线程,但是 Ractor 做了一系列的限制。首先,锁是不会在 Ractor 之间共享的;也就是说,不可能有两个线程争抢同一个锁。Ractor 和 Ractor 之间可以传递消息。Ractor 内部具有全局锁,确保 Ractor 内的行为和原先 Thread 是一致的。传递消息必须是值类型的,这意味着不会有指针跨 Ractor 生存,也会避免数据竞争问题。简而言之,Ractor 把每个 Thread 当作一个 Actor。
但 Ruby 没有真正的值类型。但值类型的本质就是用拷贝来替代引用。我们要做的就是确保 Ruby 对象的可拷贝性。我们查看 Ractor 的文档,我们可以看到这个的严格描述:
Ractors don't share everything, unlike threads.
* Most objects are *Unshareable objects*, so you don't need to care about thread-safety problem which is caused by sharing.
* Some objects are *Shareable objects*.
* Immutable objects: frozen objects which don't refer to unshareable-objects.
* `i = 123`: `i` is an immutable object.
* `s = "str".freeze`: `s` is an immutable object.
* `a = [1, [2], 3].freeze`: `a` is not an immutable object because `a` refer unshareable-object `[2]` (which is not frozen).
* Class/Module objects
* Special shareable objects
* Ractor object itself.
* And more...
Ractor 性能提升测试
为了测试出 Ractor 的效果,我们需要一个计算密集的场景。最计算密集的场景,当然就是做数学计算本身。比如我们有下面一个程序:
DAT = (0...72072000).to_a
p DAT.map { |a| a**2 }.reduce(:+)
这个程序计算 0 到 72072000 的平方和。我们运行一下这个程序,得到运行时间是 8.17s。
如果我们用传统的多线程来写,我们可以把程序写成这样:
THREADS = 8
LCM = 72072000
t = []
res = []
(0...THREADS).each do |i|
r = Thread.new do
dat = (((LCM/THREADS)*i)...((LCM/THREADS)*(i+1))).to_a
res << dat.map{ |a| a ** 2 }.reduce(:+)
end
t << r
end
t.each { |t| t.join }
p res.reduce(:+)
运行后,我们发现,虽然确实创建了 8 个系统线程,但是总运行时间变成了 8.21s。没有显著的性能提升。
使用 Ractor 重写程序,主要需要改变我们子线程内需要访问外面的 i 变量,我们用消息的方法传递进去,改进后的代码会变成这样:
THREADS = 8
LCM = 72072000
t = []
(0...THREADS).each do |i|
r = Ractor.new i do |j|
dat = (((LCM/THREADS)*j)...((LCM/THREADS)*(j+1))).to_a
dat.map{ |a| a ** 2 }.reduce(:+)
end
t << r
end
p t.map { |t| t.take }.reduce(:+)
其结果如何呢?我们根据不同的线程数量进行了测试。
| Threads | AMD Ryzen 7 2700x | Intel i7-6820HQ |
|---|---|---|
| 1 | 8.171 | 12.027 |
| 2 | 4.483 | 6.913 |
| 3 | 4.874 | 6.755 |
| 4 | 2.353 | 6.188 |
| 5 | 2.429 | 5.154 |
| 6 | 2.259 | 5.320 |
| 7 | 1.908 | 5.368 |
| 8 | 2.156 | 5.754 |
| 9 | 2.136 | |
| 10 | 3.159 | |
| 11 | 2.577 | |
| 12 | 2.679 | |
| 13 | 2.787 | |
| 14 | 2.615 | |
| 15 | 2.197 | |
| 16 | 2.303 |
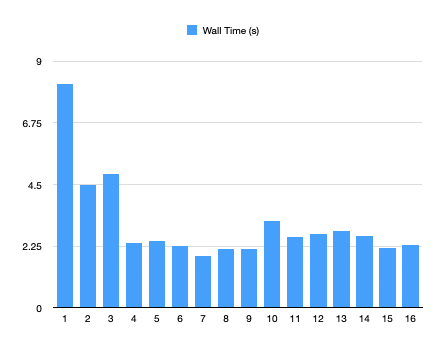
Ractor 确实改善了多线程全局解释锁的问题。
显微镜下的 Ractor
我使用了 AMD uProf(对于 Intel CPU,可以使用 Intel VTune)进行 CPU 运算情况的统计。为了降低睿频对单线程性能的影响,我将 AMD Ryzen 7 2700x 全核心锁死 4.2GHz。
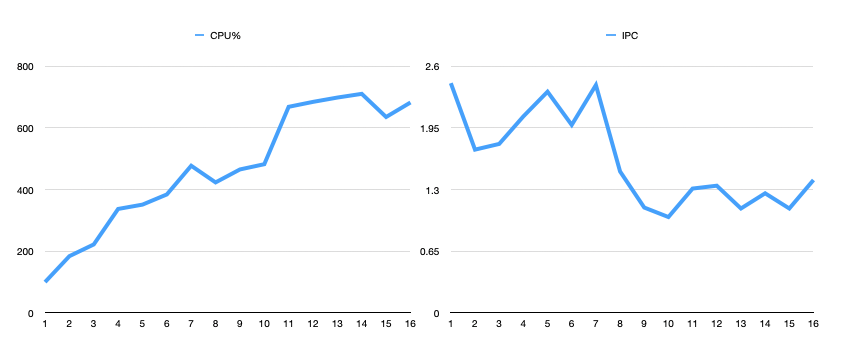
对于 AMD Ryzen 7 2700x,4 线程比单一线程快了 3 倍多。到 4 线程,比单一线程快了约 4 倍。AMD Ryzen 7 2700x 是一款 8 核心 16 线程的 CPU。同时,每 4 个核心组成一个 CCX,跨 CCX 的内存访问有额外的代价。这使得 4 线程内性能提升很显著,超过 4 线程后受限于 CCX 和 SMT,性能提升变得比较有限。其表现是随着线程数的增加,IPC(每时钟周期指令数)开始下降。在单线程运算时,每时钟周期 CPU 可以执行 2.42 个指令;但到了 16 线程运算时,每时钟周期 CPU 只能执行 1.40 个指令。同时,更多的线程意味着更复杂的操作系统的线程调度,使得多核的利用率越来越低。
同样,对于 Intel i7-6820HQ,我们得到了类似的结论。这是一款 4 核 8 线程的 CPU,由于第 5 个线程开始需要使用 HT,从而提升变得很有限。
Ractor 如何改善现有 Ruby 程序的性能?
Ractor 的引入除了可以改善计算密集场景下的运算效率,对于现有大型 Ruby Web 程序的内存占用也是有积极意义的。现有 Web 服务器,比如 puma,由于 I/O 多路复用性能极其低下,通常会使用多线程 + 多进程的形式来提升性能。由于 Web 服务器可以自由水平扩展,使用多进程的形式来管理,可以完全解开 GIL 锁的问题。
但是 fork 指令效率低下。微软在 2019 年 HOTOS 上给出了一篇论文:A fork() in the road,和 spawn 相比,fork 模式会导致启动速度变得非常慢。为了缓解这一问题,在 Ruby 2.7 引入 GC.compact 后,通常需要执行多次 compact 来降低 fork 启动的消耗。进一步地,使用 Ractor 来替代多进程管理,可以更容易地传递消息,复用可冻结的常量,从而降低内存占用。
总结
Ruby 3 打开了多线程的潘多拉盒子。我们可以更好利用多线程来改善性能。但是看着 CPU Profiler 下不同线程调用会导致 CPU IPC 下降和缓存命中下降,对程序调优也提出了更高的要求。
我们边走边看吧。
Comments